財務取證的基礎數據分析
不需大數據,只需基礎資料
[An English Version: https://medium.com/discourse/data-analytics-for-financial-forensics-8b762b84bb56]
如今,當我們幾乎將生活的每個方面都數字化,電子數據幾乎無所不在,大數據 (Big Data) 已廣泛地應用在分析和預測商業收支等功能,在電子商貿上的應用具有強大的通用性。然而,它可能不太適用於金融取證 (Financial Forensics)。儘管大數據為分析人員提供了3V:大量信息 (Volume),多種數據類型 (Variety) 和高速數據流 (Velocity),但是所有這些數據都可以被操縱,甚至被偽造!最近的一個案例表明,金融法證學家採用基本甚至原始的數據收集方法來調查某些公司數據的可靠性和準確性,以查證在大數據上的造假。
Badkar&Henderson的《金融時報》(2020年)報導說:“一家在美國上市的中國教育公司被做空者指控其虛假銷售後,面臨美國證券監管機構的調查。”該指控主要來自於一家美國上市公司的一份報告。研究公司於2020年5月成立。這是繼納斯達克證券交易所(Nasdaq Stock Exchange)因“去年一家咖啡連鎖店披露某些費用和支出被“大幅誇大”,及把銷售金額造假了價值22億元人民幣(3.22億美元)”而導致退市之後的第二起案件。
他們是如何發現這些“偽造數據”?它不是通過任何大數據方法或機器學習技術 (Machine Learning) 所能達到。相反,它是通過最基本的數據收集方法進行的。根據 Anonymous(2019)的一份報告,他們``動員了92名全職和1,418名兼職人員在現場進行監視,並成功記錄了981個商店日的商店流量,覆蓋了620家商店營業時間的100%。'' (p.4)這種方法不僅需要大量人力來覆蓋一段時間內位於38個城市的商店數量,而且還依賴最原始的數據收集方法,即直接計算每間商店的人流量和從商店到商店關門的錄製短片(視頻),平均每天錄影時間達11.5小時。
其計算模型如下:
每個商店每天的訂單數 = 提貨的顧客數量 + 送貨人員提起的紙袋數量…(1)
每家商店每天的項目數量 = 每家商店每天的訂單數量 x 每份訂單的項目數量…(2)
第(1)式的數據可以直接從短片(視頻)中計算拿起產品的客戶數量和派送人員拿起的紙袋數量。每張訂單的項目數設定為1.14。(第15頁)如何得出此數字有點困難且費神,詳述如下:
“他們從45個城市的2,213家商店中的10,119位客戶那裡收集了25,843張客戶收據。 25,843張收據分別表示取件和交貨單的每個訂單分別有1.08和1.75件,或合計為1.14。”(第20頁)
然而,最棘手的技術是跟踪每天每家商店的訂單數量。”由於所有訂單都是「在線」下達和付款的,只是取貨是離線進行,因此在下訂單時,系統自動產生一個三位數的取件號碼和一個QR碼,以方便在店內取貨。 …三位數的提貨號碼在一天中的每間商店中順序出現,提貨單和送貨單共享提貨號碼”。(第16頁)
但是調查人員如何才能知道每一家商店每天的三位數提貨碼?
這是這項研究中最關鍵的方法之一-[他們]“在商店營業時間的開始和結束時各下一個訂單,以獲取當天的在線訂單號數。”(第17頁)
除了跟踪訂單數量外,他們還比較每件商品的實際和聲稱的平均售價。由於他們已經收集了25,843張收據,收據上指明了每件商品的售價。這些收據成為估計每件商品平均售價的樣本。該報告聲稱,“ 25,843張收據表明……相對於所報告的[平均售價]情況,誇大率達……12.3%。”(第24頁)但是,它沒有詳細說明收據是如何收集的以及如何避免選擇偏差 (selection bias)。
上面的討論旨在表明一種好的研究方法對數據取證的重要性。它不一定需要人工智能或大數據技術。有時,原始的方法是最強而有力的,尤其是當二手數據不可靠時。無論AI多麼高智能,大數據分析的結果都取決於原始數據的可靠性。所謂「垃圾進垃圾出」,假數據進假結論出!
誠然,這也表明一個簡單的研究項目可以很昂貴。例如,上述研究的一小部分:商店的短片(視頻)記錄便需要981個商店日x 11.5小時的每天工資,即11,281.5個商店小時。即使兼職研究人員的每小時工資為5美元,也要花費56,407.5美元 (若值港元44萬元)!
這種直接觀察的原始方法聽起來技術含量低,而且人力資源消耗大,但若一項良好設計的直接觀察方法可以在科學研究中發揮強大功用。我與團隊在十年前的研究中也嘗試過類似的方法(Yiu & Ng,2010),當然,我們沒有那麼多資源來進行如此大規模的研究,但是基本方法或多或少是相同的,該研究也是關於零售顧客的,題目為《購物者與閒逛者比例研究》。
長期以來,閒逛者與購物者的比率一直是用於評估購物商場零售表現的重要指標,但通常這項數據是通過向顧客進行問卷調查來確定,這在很大程度上是取決於回應的可信度。為了弄清楚實際的購物者與閒逛者比率,我僱用了一組兼職學生對購物商場中的購買者和閒逛者數量進行直接計算。
我們總共收集了810個觀察結果(包括購物者和閒逛者),其中有540個樣本是在工作日收集的,其餘270個是在周末收集的。換句話說,我們的3x 3x 3數據是3天內在3處購物商場的3類連鎖店中購物者與閒逛者比率的實際觀察值。每個觀察中記錄的信息包括(1)是否有購物; (2)購物者的性別和年齡段(由調查員估算); (3)購物者在商店停留多長時間; (四)店鋪類型; (5)時間(工作日或週末); (6)地點(購物中心名稱)。
表1顯示了直接在購物中心觀察到的購物者與閒逛者比率。首先,它們比對在相同購物商場內進行的問卷調查中所獲得的數據要小得多。例如,平均超過53%和43%的受訪者表示他們購買了一些服裝和視聽/電氣產品,但只有大約26%和16%的人士在該類商店內能觀察到有購物。這些結果引起了大家對閒逛者與購物者比率研究以及零售研究中使用問卷和訪談的可靠性的疑問。
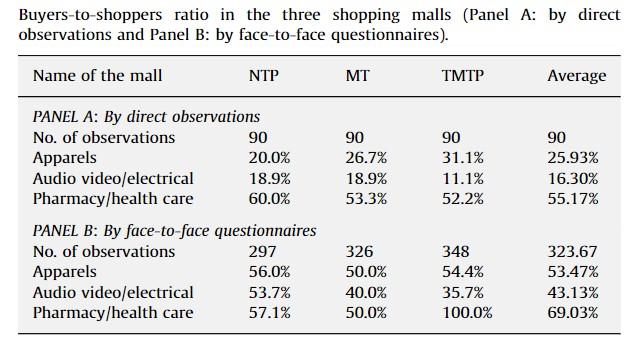
表1 買者與購物者比率研究的結果之一。資料來源:Yiu & Ng(2010)
與Anonymous(2019)的研究相似,我們的學生在直接計算過程中遇到了一些困難。例如,即使他們只是站在商場那兒觀察,他們也被一些管理人員攔住了,在此必須再次感謝學生們在完成數據收集過程中所付出的努力。 Anonymous(2019)案的情況似乎更加糟糕,它的報告說,“有851個營業日因未能記錄一整天的短片(視頻)而須取消整日的數據,失敗的原因包括:被店舖員工要求停止攝錄,設備出問題或質量控制失敗等,因為這些每日短片缺少超過10分鐘以上,該營業日數據便不會包括在數據分析中。”
參考文獻
Badkar, M. & Henderson, R. (2020). SEC probes US-listed Chinese education company GSX Techedu, Financial Times, Sep 3. https://www.ft.com/content/42ce7af3-73fc-43a5-827e-a362beb9bce0
Anonymous (2019). Luckin Coffee: Fraud + Fundamentally Broken Business, MuddyWatersResearch, Twitter, Feb 1. https://twitter.com/muddywatersre/status/1223274746017722371?lang=en, and the report at https://drive.google.com/file/d/1LKOYMpXVo1ssbWQx8j4G3-strg6mpQ7F/view
Yiu, C.Y. & Ng, H.C. (2010). Buyers-to-shoppers ratio of shopping malls: A probit study in Hong Kong, Journal of Retailing and Consumer Services. 17(5), 349–354. https://doi.org/10.1016/j.jretconser.2010.03.016